Здравствуйте, гость ( Вход | Регистрация )
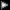

 15.04.2004, 21:00 15.04.2004, 21:00
Сообщение
#1
|
|
|
Очень хорошо  Группа: Пользователи Сообщений: 55 Регистрация: 8.05.2003 Пользователь №: 111 |
PCI Express - шина будущего
Шина PCI (Peripheral Component Interconnect) широко используется в качестве универсальной шины ввода/вывода уже на протяжении более десяти лет, однако сегодня она уже вплотную подошла к своим пределам. Расширения стандарта PCI, типа 64-битных слотов и тактовой частоты 66 МГц или 100 МГц, слишком дороги и вряд ли успеют угнаться за растущими потребностями в высокой пропускной способности в следующие несколько лет. В качестве замены устаревающей PCI выдвинута шина ввода/вывода третьего поколения (3rd Generation IO, 3GIO), которая не так давно была переименована в PCI Express. Новейшая история Спецификация PCI 1.0 была выдвинута Intel в далёком 1991 году. Разработкой PCI занималась группа PCI Special Interest Group, в результате работы которой уже в мае 1993 года появилась версия PCI 2.0. Главным конкурентом новой шины являлась VESA Local Bus (VL-bus или VLB), разработанная Ассоциацией по стандартам в области видеоэлектроники (Video Electronics Standards Association) и представлявшая собой 32-битную шину, которая использовала третий и четвёртый разъём в виде продолжения обычного слота ISA. Шина работала на номинальной частоте 33 МГц и обеспечивала существенный прирост производительности по сравнению с ISA. Поскольку шина VLB работает синхронно с процессором, увеличение частоты процессора приводило к появлению проблем с периферией VLB. Чем быстрее должна была работать периферия, тем она дороже стоила по причине трудностей, связанных с производством высокоскоростных компонент. Лишь немногие устройства VLB поддерживали скорость выше 40 МГц. Шина PCI обладала несколькими преимуществами по сравнению с VLB. Она была разработана в качестве промежуточного решения: PCI являлась отдельной шиной, изолированной от процессора, однако она сохранила доступ к основной памяти. Шина получила возможность асинхронной работы от процессора с номинальными частотами 25 МГц, 30 МГц и 33 МГц. По мере роста скоростей процессора частота шины PCI могла оставаться постоянной и составлять какую-то долю от шины FSB. Шина поддерживала удвоенное число слотов и/или периферийных устройств по сравнению с VLB - пять или больше, без всяких ограничений частоты или буферизации. Другие "умные" функции облегчали использование PCI. Технология Plug and Play позволяла производитель автоматическую конфигурацию периферии без настройки IRQ, DMA и адресов ввода/вывода через перемычки. К тому же шина поддерживала разделяемые между несколькими устройствами IRQ, а также и свою собственную систему прерываний (она скрывается за обозначениями #A, #B, #C и #D). Наконец, управление шиной PCI (PCI bus mastering) позволяло устройствами на шине получать контроль над ней и производить прямые передачи информации без участия процессора. В результате снижались задержки и нагрузка на процессор. Введение шины вместе с процессором Pentium, усиленное очевидными преимуществами над конкурентами, позволило PCI выиграть войну шин и стать доминирующим стандартом в 1994 году. С тех пор практически все периферийные устройства, от контроллеров жёстких дисков и звуковых карт до видеокарт и сетевых плат, базировались на шине PCI. С распространением массивов RAID, гигабитного Ethernet и других устройств с высокой пропускной способностью на системах потребительского класса, пропускной способности PCI в 133 Мбайт/с стало не хватать. Производители чипсетов предвидели эти ограничения и вносили в свою продукцию различные изменения, чтобы снять часть нагрузки с шины PCI. До 1997 года графическая подсистема наиболее сильно нагружала шину PCI. Выпуск вместе с чипсетом Intel 440LX ускоренного графического порта AGP (Accelerated Graphics Port) послужил двум целям: увеличить графическую производительность и убрать графические данные с шины PCI. Однако AGP явился лишь первым шагом в деле уменьшения нагрузки шины PCI. После этого производителям чипсетов пришлось переделать связь между северным и южным мостом. Старые чипсеты, типа линейки Intel 440, использовали шину PCI для связи между мостами. Шине PCI приходилось не только передавать информацию между мостами, но и обслуживать другие устройства PCI, в том числе IDE, Super I/O (параллельный и последовательный порты, PS/2), а также USB. Чтобы исправить ситуацию, Intel VIA и SiS стали использовать для связи северного и южного мостов специальную высокоскоростную линию, а затем перенесли IDE, Super I/O и USB на собственные выделенные линии к южному мосту. Наконец, в апреле Intel анонсировала архитектуру CSA, поддерживаемую северным мостом чипсетов i875/i865, убрав гигабитный Ethernet с шины PCI. Если AGP, CSA, Intel Hub Link, VIA V-Link и SiS MuTIOL можно назвать относительно успешными решениями в деле снятия нагрузки с шины PCI, они являются лишь промежуточными вехами. Новая шина Шина PCI Express, ранее известная как шина ввода/вывода третьего поколения (3rd Generation I/O, 3GIO), призвана заменить шину PCI и взять на себя задачу по связи компонентов внутри компьютера на ближайшие десять лет. Она разработана с учётом применения на множестве сегментов рынка, в роли единой архитектуры ввода/вывода для настольных ПК, мобильных решений, серверов, устройств связи, рабочих станций и встроенных устройств. Напомним, что оригинальная спецификация разрабатывалась только для сегмента настольных ПК. Что касается стоимости внедрения, то новая шина призвана соответствовать уровню PCI или даже быть ниже него. Последовательная шина требует наличия меньшего числа проводников на печатной плате, облегчая дизайн платы и увеличивая его эффективность - ведь освободившееся место можно использовать для других компонентов. Шина поддерживает совместимость с PCI на программном уровне, то есть существующие операционные системы будут загружаться без каких-либо изменений. Кроме того, конфигурация и драйверы устройств PCI Express будут совместимы с существующими PCI-вариантами. Масштабируемость производительности достигается через повышение частоты и добавление линий к шине. PCI Express призвана обеспечить высокую пропускную способность на контакт с низким количеством служебной информации и низкими задержками. Поддерживаются несколько виртуальных каналов на один физический. Шина может работать и в качестве соединения "точка-точка", когда устройства не разделяют общую шину. Среди других преимуществ следует отметить: возможность эффективно работать с различными структурами данных; низкое энергопотребление и поддержку функций энергосбережения; качество стратегий обслуживания; поддержку "горячей замены" и "горячей установки" устройств; обеспечение целостности данных и обнаружение ошибок на нескольких уровнях; изохронную передачу данных; узловую передачу при использовании чипов-мостов и одноранговую передачу с помощью коммутаторов; многоуровневую технологию с поддержкой пакетной коммутации. На самом деле PCI Express представляет собой целый аппаратный комплекс, затрагивающий северный/южный мост, коммутатор и конечные устройства. Новым термином здесь является коммутатор (switch). Он заменяет шину с множественными подключениями коммутируемой технологией. Коммутатор обеспечивает одноранговую связь между различными конечными устройствами, то есть предотвращает попадание излишнего трафика к мосту. Архитектура PCI Express состоит из уровней, что облегчает кросс-платформенный дизайн. В самом низу находится физический уровень (Physical Layer). Основной физический принцип связи PCI Express заключается в использовании двух дифференциальных сигналов с низким напряжением для приёма и для передачи. Встраивание сигнала данных с помощью схемы кодирования 8/10b позволяет достичь высоких скоростей передачи. Изначальная пропускная способность составляет 2,5 Гбит/с в каждом направлении, причём по мере развития кремниевых технологий скорость передачи будет расти. Возможно достижение пропускной способности 10 Гбит/с в обоих направлениях. Одна из наиболее впечатляющих функций PCI Express заключается в возможности масштабирования скорости, используя несколько линий передачи. Физический уровень поддерживает ширину шины X1, X2, X4, X8, X12, X16 и X32 линий. Передача по нескольким линиям прозрачна для остальных слоёв. Канальный уровень (Data Link Layer) гарантирует надёжную передачу и целостность данных для каждого пакета, переданного по связи PCI Express. Помимо использования нумерации пакетов и контрольной суммы CRC канальный уровень применяет протокол управления потоком с разрешениями на передачу, который передаёт данные только в случае готовности буфера приёма на принимающей стороне. В результате этого число повторов пакетов снижается, что позволяет более эффективно использовать пропускную способность шины. Ошибочные пакеты передаются повторно. Уровень транзакций (Transaction Layer) создаёт пакеты и передаёт информацию от программного уровня на канальный уровень в виде отдельных транзакций. Каждый пакет имеет уникальный идентификатор, также уровень поддерживает 32-битную или расширенную 64-битную адресацию памяти. Дополнительные функции включают "no-snoop", "relaxed ordering" и установку приоритетов, что позволяет осуществлять маршрутизацию и задавать качество обслуживания QOS. Более того, уровень транзакций знаком с четырьмя адресными пространствами: память, пространство ввода/вывода, конфигурационное пространство (три этих пространства уже существовали в спецификации PCI) и новое пространство сообщений Message Space. Последнее позволяет заменить сигналы боковой полосы частот (side-band) в спецификации PCI 2.2 и убрать все "специальные циклы" старого формата. Сюда относятся прерывания, запросы управления энергосбережением и сброс. Наконец, программный уровень (Software Layer) отвечает за программную совместимость. Процесс инициализации и работы с устройствами шины остался неизменным по сравнению с PCI, что позволяет существующим операционным системам поддерживать PCI Express без всяких изменений. Устройства нумеруются таким образом, чтобы операционная система смогла обнаружить их и выделить необходимые ресурсы, в то время как работа с шиной построена на модели PCI загрузка-сохранение с разделяемой памятью. Впрочем, нам ещё предстоит увидеть, будет ли требоваться модификация на самом деле, поскольку "поддержка PCI Express" заявлена как одна из функций следующей операционной системы Microsoft с кодовым названием Longhorn. Тонкий намёк, что предыдущие операционные системы могут и не поддерживать PCI Express. Среди других инноваций следует отметить использование отсеков устройств, позволяющих осуществлять "горячую замену". Мобильные пользователи не остались без внимания, поскольку для них предложен новый стандарт PCMCIA с кодовым названием NEWCARD. Форм-фактор нового стандарта таков, что карта NEWCARD практически в два раза уже одной карты CardBus. К сожалению, стандарт не предназначен для поддержки графических решений, так что пользователи ноутбуков вряд ли смогут модернизировать свои видеокарты. Однако возможности расширения относительно других устройств практически безграничны. Поскольку PCI Express обеспечивает скорость передачи 200 Мбайт/с уже при ширине X1, шина является очень эффективным решением по отношению стоимость/число контактов. На повестке дня находится ещё один вопрос: начнёт ли PCI Express новую войну шин с другими решениями типа PCI-X и HyperTransport? Рабочая группа PCI Express, Arapahoe, утверждает, что эти шины нацелены на другие области. RapidIO и HyperTransport были разработаны для специфических применений, в то время как PCI Express выступает в роли универсального варианта. Вряд ли PCI Express сможет заменить HyperTransport в качестве связи между процессорами. PCI Express не хватает протокола когерентности кэшей, к тому же шина обладает более длительными задержками, чем параллельные проводники с синхронизацией по источнику. Очевидно, что AMD и nVidia бояться нечего. Заключение PCI Express обладает великолепным потенциалом. Шина позиционируется как универсальное решение для связи компонентов платы и имеет очевидные преимущества по гибкости, что гарантирует её пригодность для широкого диапазона вариантов реализации. Как и другие важные изменения, переход с PCI на PCI Express не случится за одну ночь. Слоты ISA жили на платах почти 10 лет, перед тем как они наконец-то исчезли. Так что не следует полагать, что периферия PCI скоро отомрёт. Спецификации PCI Express Base 1.0a Specification и Card Electromechanical 1.0a Specification уже утверждены, хотя вряд ли мы увидим какие-либо решения на базе PCI Express до 2004 года. Вероятно, первыми появятся видеокарты от nVidia и ATi, сопровождаемые материнскими платами на новом чипсете Grantsdale от Intel. Что касается серверной стороны рынка, Intel планирует выпустить PCI Express в паре с чипсетами Lindenhurst и Twin Castle. Будущее выглядит в радужных тонах, на что немало влияют новые форм-факторы и потенциально высокая производительность. |
 |


 
|



 |
Ответов
|
15.04.2004, 21:00
Сообщение
#2
|
|
|
Очень хорошо Группа: Пользователи Сообщений: 55 Регистрация: 8.05.2003 Пользователь №: 111 |
PCI Express
Поскольку с проблемой недостаточной скорости обмена данными между компонентами системной логики в компьютерах сталкиваются абсолютно все, компания Intel, как крупнейший поставщик полупроводников в мире, также решила представить свое видение решения. Первым шагом отказа от PCI в качестве шины, соединяющей северный и южные мосты чипсетов стало представление в конце 1998 года набора микросхем i810, где для соединения GMCH (Graphics and Memory Controller Hub, экс-северный мост) и ICH (I/O Controller Hub, экс-южный мост) использовался Intel Hub Architecture 1.0, позволяющий передавать до 266 MB в секунду. В настоящее время, Intel полностью отказался от применения PCI в соединениях чипсетов для настольных ПК и перешел на Intel Hub Architecture 1.0/1.5, а также на PCI-X в серверных платформах (где оно будет с успехом использоваться чуть ли не 2005 года). В общем и целом, скорость межкомпонентной передачи данных у Intel не стоит столь остро, как у конкурента: Quad Pumped Bus способна загрузить данными Pentium 4, а производительности памяти DDR-II или двух каналов обычной DDR SDRAM вполне хватит как на сегодняшний, так и на завтрашний день. А как насчет послезавтра? Процессоры послезавтрашнего дня будут уметь обрабатывать огромные массивы данных и, как следствие, многократно возрастут требования к пропускной способности шин. Вполне возможно, что следующим поколениям процессоров не хватит производительности Quad-Pumped Bus, а периферия сможет захотеть чего-то большего, нежели PCI 2.2 или PCI-X. С оглядкой на очень отдаленное будущее корпорация Intel приступила к разработке нового протокола данных, который должен будет использоваться в компьютерах начиная с середины десятилетия. Результатом этой работы стала технология 3GIO (Arapahoe), ныне называемая PCI Express. Требования, которые выставляются к следующему поколению соединений, у Arapahoe Group в целом аналогичны тому, что выставляет HyperTransport Technology Consortium: Универсальность и поддержка всех видов платформ – настольные ПК, переносные компьютеры, сервера, рабочие станции. В перспективе использование шины должно также перейти на коммуникационное и промышленное оборудование. Масштабирумость – применение шины должно быть эффективным, а значит, легко изменяться под конкретные требования конкретной системы. Масштабируемость также означает гибкость стоимости внедрения. Высокая скорость и низкая латентность. Низкая цена и высокая производительность - стоимость должна быть ниже, а производительность выше PCI стандарта. Отношение скорости к цене должно быть выгодным, попросту говоря, чем меньше проводников требуется для обеспечения высокой пропускной способности – тем лучше. Обратная совместимость с текущими стандартами – поскольку накоплен огромный парк программ, операционных систем, драйверов и т.д. для устаревающего PCI, обратная совместимость новой шины к PCI пришлась бы к месту и была бы незаменима во многих случаях, например, на производстве. Совместимость с другими шинами передачи данных – возможность работать с разными видами устройств. Дополнительные возможности – шина должна уметь работать с различными видами данных, управлять энергопотреблением компонентов, поддерживать смену add-on устройств в рабочем состоянии, обеспечивать целостность данных и коррекцию ошибок. При этом, Arapahoe не ставит перед собой цели создать протокол передачи данных для процессоров, банков памяти, межблочного соединения для кластерных решений и т.д.. Однако, планирует, что внешние устройства смогут соединяться напрямую с PCI Express посредством коннектора, иными словами, компьютер и впрямь имеет шансы стать центром соединений всех видов устройств через одну единственную шину. Последнее даст толчок грандиозной унификации всех устройств. Концепция PCI Express Огромное количество параллельных шин явно не способствую удешевлению компьютеров, также как зачастую не дают возможность увеличивать их производительность. Очевидно, что идеально иметь одну последовательную шину, на которую устанавливать все необходимые устройства, обеспечивая масштабируемость платформы. Вторая часть концепции заключается в возможности изменения полосы пропускания в зависимости от необходимости. Для последнего следует соединять устройство напрямую с мостом (Host Bridge) или коммутатором по методу «точка-точка» (peer-to-peer). Однако, и в случае последовательной шины мы должны иметь в виду, что при определенных условиях пропускной способности определенного соединения может не хватить для одновременной передачи множества пакетов. Этот случай будет особенно заметен при обработке потоков в реальном времени, когда любая задержка является критичной. Для потенциального нивелирования такой ситуации, PCI Express присваивает пересылаемым пакетам атрибуты, характеризующие приоритетность их обработки: низкий «no-snoop», средний «relaxed-ordering» и приоритетный «priority» (все читатели, знакомые с английским, оценивают юмор инженеров Intel :-)). Так, или иначе, но концепции и цели у HyperTransport и PCI Express фактически одинаковые, а разница между подходами не может считаться диаметрально разной, особенно с учетом того, что AMD, наряду с Dell, Compaq, Intel, ATI Technologies и другими также участвует и в комитете по разработке и внедрению PCI Express. Принципы работы PCI Express Дабы иметь возможность хотя бы поверхностно сравнивать шины HyperTransport и PCI Express, попытаемся разобраться в основных принципах работы второй. Общая структура шины представлена на иллюстрации ниже:  Структура PCI Express состоит из компонентов, обычных для любой шины данных: Протоколы инициализации и конфигурации. Протоколы адресации/чтения-записи. Протокол передачи данных. Контроль циклическим избыточным кодом (CRC). Физическое воплощение всего вышеупомянутого – меняется в зависимости от устройства. Первые два пункта, также как у Hyper Transport, соответствуют тому, что мы используем с PCI, за тем исключением, что теперь системные прерывания будут передаваться посредством виртуального MSI (Message Signaled Interrupt) вместо аппаратного сигнала по боковой полосе. Поскольку MSI является опцией в PCI 2.2, особых проблем с переходом на него возникнуть не должно. Метод контроля за ошибками также традиционен и представляет собой обычную контрольную пару бит (каждый байт информации передается как 8бит/10бит). К сожалению, большим количеством информации о физическом воплощении PCI Express мы поделиться не можем. Дело в том, что согласно всем планам Arapahoe Group его окончательные спецификации будут доступны лишь во второй половине текущего года с появлением тестового оборудования ориентировочно еще через год и реальных коммерческих продуктов в 2004. Как уже многократно говорилось, будущие шины данных не будут иметь фиксированных скоростей: в разных случаях будут использованы соответствующие решения, удовлетворяющие в исключительно данной ситуации. Пропускная способность и тактовая частота работы шины передачи данных PCI Express может варьироваться: клокинг увеличивается или уменьшается, магистраль, соответственно, расширяется или сужается. Первоначально на физическом уровне будет поддерживаться ширина линий х1, х2, х4, х8, х16 и х32 в одно направление. Интегрированный в системный мост или специальный коммутатор агент PCI Express эффективно распределит поток перед тем, как отправлять его по разным физическим линиям, а впоследствии, аналогичный агент соберет разные потоки данных в один, как это показано на схеме.  На данном этапе PCI SIG не декларирует тактовой частоты работы шины, ограничиваясь словами о пропускной способности в 2.5 ГБ/сек в одном направлении при использовании 16 битной магистрали (2 по 8 бит) и 40 контактах. Путем несложных математических подсчетов можно получить скорость передачи данных примерно в 2.5 ГГц, что намного выше предполагаемой у HyperTransport. Именно высочайшая тактовая частота соединения должна обеспечить жизнь PCI Express на десять лет вперед. Более того, традиционное соединение PCI для add-on устройств будет заменено на PCI Express тогда, когда это будет необходимо. Причем новый слот будет состоять из привычного PCI гнезда (для облегчения перехода) и дополнительного коннектора.  Собственно говоря, с год назад Intel выдвинул идею перехода с AGP на Serial AGP , который будет являться производной от последовательной шины PCI Express. Стоит отметить, что произойдет это очень не скоро: в 2005-2006 годах. Думается, что замена традиционному PCI вряд ли потребуется еще лет 6-7, потому, рисунок выше – своеобразный раритет, которого мы не увидим еще очень долго. Назад в будущее: Заключение Мы рассмотрели двух представителей межкомпонентных соединений, которые войдут в наши ПК совсем скоро. Оба протокола рассчитаны на многие годы и, судя по набору возможностей, трудно сказать, который из них будет более удачливым. Следует отметить, что фундаментальная разработка HyperTransport уже завершена, продукты с его применением можно встретить на рынке: это и консоль Microsoft XBOX и материнские платы на базе чипсетов Nvidia Nforce. Через несколько месяцев выходит семейство процессоров AMD Hammer, где HyperTransport выполняет роль системной шины. Кроме того, технология будет применяться в огромном спектре коммуникационных устройств, что должно вывести разработки AMD на новый уровень. В общем и целом, в течение ближайшего года - двух мы будем наблюдать победное шествие HyperTransport по всей отрасли. Где-то в 2004-2005 годах на горизонте появится PCI Express, продвигаемый Intel, он должен за очень короткий срок быть внедрен в компьютеры всех классов: от low-end до серверов. На какое время хватит масштабируемости HyperTransport, и сможет ли эта технология противостоять PCI Express - вопрос. С одной стороны, к 2004 году, когда появятся первые ласточки PCI Express, HyperTranport будет использоваться повсеместно, а значит, ведущие игроки индустрии могут не захотеть чего-либо менять в ситуации, особенно, если учесть, что на первый взгляд PCI Express не обладает существенными преимуществами. С другой стороны, Intel внедрит PCI Express в свои чипсеты, что автоматически означает довольно большое распространение. Впрочем, не следует думать, что Intel может предложить рынку любое решение, которое будет принято только благодаря авторитету компании. Как мы имели возможность наблюдать, пресловутый RDRAM, который продвигался корпорацией с середины 1999 года был отвергнут индустрией как непрактичный, даже несмотря на очевидную привлекательность с точки зрения технологии. В общем, поживем – увидим. Вполне может случиться и так, что HyperTransport и PCI Express вообще окажутся представителями разных эпох в компьютерной индустрии. Быть может, мы столкнемся с очередным матчем “AMD Vs Intel” в новом виде. Ставки, правда, на этот раз, будут гораздо больше, чем части сегментов рынка процессоров для ПК... |
|
|
|
Сообщений в этой теме


 |
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0
| Текстовая версия | Сейчас: 9.07.2025, 1:18 |